
Redundancy Revenue: An Elastic Failover Exchange to turn your competitor's downtime into dollars
Redundancy is just a digital insurance policy that currently costs far too much, and pays out far too little - so why not share and trade it to monetize what you've already got?

Redundancy Today: Safe but Wasteful
In traditional infrastructure design, redundancy means duplication. One server fails, another takes over; or one data center goes offline, another picks up the load.
It's reliable, but it's also inefficient; with most data centers typically running with between 40–60% of their capacity unused, as a large proportion of the infrastructure and architecture is just dedicated to backup scenarios.
If we think about redundancy strategies as an insurance policy - the current state is madness:
Redundancy is just a digital insurance policy that currently costs far too much; and realistically pays out far too little to justify that expense.
I have no clue on the exact figures for this, but it's safe to say that if 50% of the hardware infrastructure cost of nearly all data centers is purely for redundancy protocols, then it must be billions of dollars invested in idle hardware; megawatts of unused energy; and square kilometers of underutilized rack space.
The smart loading systems do aim to use some of this capacity during periods of intense operations; but it's still not optimal - such capacity is only monetized to a partial degree - and likely never enough to justify the cost of the capital outlay. Existing infrastructure nearly has to work for double the rate of return to cover the costs of it.
We need to come up with a method of monetizing the redundancy architecture better - it needs to be elastic, flexible, and pre-determined. Short term and affordable for a customer; but generating an additional revenue stream for the operator.
Today's concept is what I'm dubbing as an Elastic Failover Exchange. This could also be thought as 'Redundancy as a Marketplace' - and is effectively commoditizing redundancy capacity to be bought for short term periods.

Redundancy as A Liquid Resource
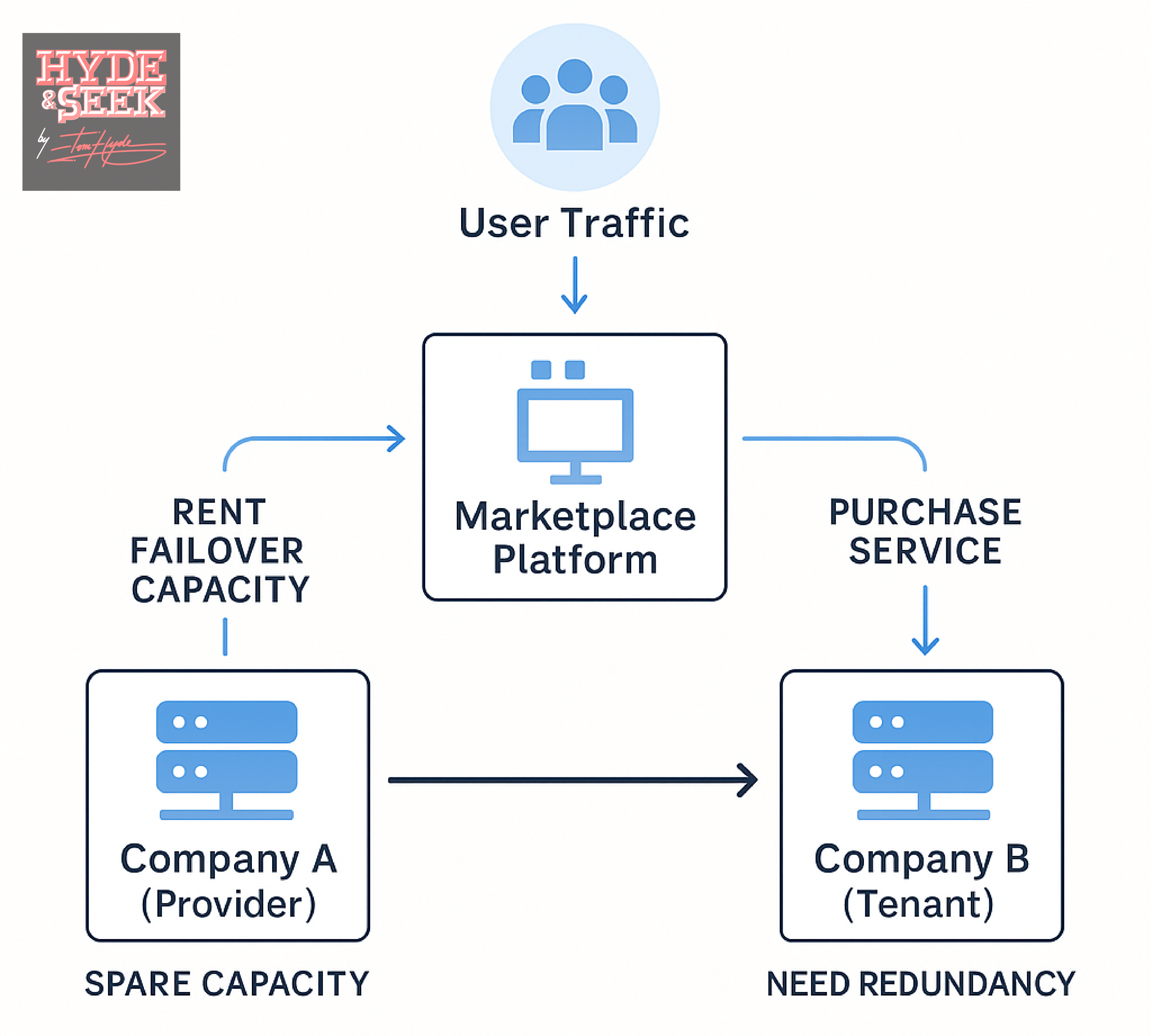
So what's the use case for this? Consider the example:
Company A has spare compute capacity in Singapore.
Company B, in the same region, wants to run disaster recovery drills or prepare for the typhoon season, where they could be a potential outage.
Instead of over-provisioning their own infrastructure, Company B rents failover capacity from Company A — just for a week, or a day.
This is the basis for the Elastic Failover Exchange:
A system where failover capacity is bought, sold, rented, or shared — not statically owned.
This is a concept which is already relatively well tried and tested in other domains - and infact, can create a staple income stream once the market is matured and solidified.
Electricity markets: Providers buy/sell surplus power, especially in grids with renewables.
Spot cloud pricing: Cloud providers monetize unused capacity dynamically.
Bandwidth peering: Network capacity is traded between ISPs to ensure balance and efficiency.
In theory, there's no reason why we can't compute redundancy.
The Mechanisms and Monetization
1. A Redundancy Exchange Platform, selling Smart Contracts or SLAs.
A digital marketplace (for instance, easily integrated into AWS Marketplace or Meta could be positioned to operate a similar service from their experience in marketplace also);data center operators and providers list available "redundancy slots".
Tenants purchase redundancy as a time-bound service with defined SLA. Redundancy commitments are governed by enforceable contracts.
This would be very similar to spot instances, but for failover infrastructure with guarantees.
2. Mechanised and Orchestrated by APIs
Failover orchestration systems (like Kubernetes, Nomad, or OpenShift) connect to the marketplace to claim and activate backup infrastructure dynamically.
3. Real-Time Monitoring + Monetization
Usage-based billing triggers only when a failover event happens.
Idle time can be billed at a discount — or zero, depending on the model.
The Win-Win Window of Opportunity
M<onetization windows of time assists both startup businesses and data center operators - slots are only sold when capacity exists. In terms of implementation, a team far more intelligent than me with software could probably get this implemented and rolled out fairly rapidly, for little to no cost to operators with significant software skills in the workforce.
Cloud-native architectures: Stateless, containerized apps can be spun up anywhere.
Observability tooling: We can measure failover success and SLA compliance in real time.
Sustainability goals: This model reduces carbon and energy waste by maximizing active utilization.
Economic pressure: Enterprises want resilience without doubling their cost base.
Providers and Operators (sellers) - Monetize idle infrastructure instead of wasting it.
Buyers (businesses/tenants) - Get access to data redundancy capacity without having to undergo any capital expenditure.
Cloud & Colocation Operators - Have an opportunity to add a new service tier, positioning failover as a revenue stream.
Sustainability teams - Reduce footprint by minimizing unused hardware.
Addressing the Challenges - Not Perfect, but Pretty Close
There are a handful of challenges that would need to be realistically considered, but nothing which would be hugely difficult to overcome - and there's likely already existing systems which could be replicated to address them:
1. Trust & SLA Guarantees - What if failover capacity isn’t available when needed?
Likely overcome by the use of verified contracts, auditing, and automated checks (blockchain, escro systems, etc.).
2. Latency / Data Locality - Some failover needs ultra-low latency or regional compliance.
This is where the beauty of the marketplace can come in. Buyers and sellers within jurisdictional or regulatory boundaries can be matched algorithmically. Local redundancy markets could form within metros or countries.
3. Security & Tenant Isolation
The platform must enforce strict multi-tenancy and container/network isolation, like any public cloud. This should be a basic service component which nearly all operators or providers will be doing already as part of their other services.
Some Potential Use Cases, and What It Enables
Use cases could include:
Startup clusters buying DR capacity from hyperscale-friendly regions.
Colocation facilities sharing excess with partner sites.
Edge infrastructure providers offering redundancy to local governments or health systems.
Multi-cloud failover without vendor lock-in.
and in turn, a successful implementation would result in:
A circular economy for compute.
More democratic access to disaster recovery — especially for small and medium enterprises.
Reduced global energy waste.
Better ROI on infrastructure investment.
Redundancy doesn’t have to be static, nor wasteful. It can be a shared, traded, and intelligent layer of infrastructure — where resilience is a product, not just a cost.
The cloud taught us that compute should be elastic, and so there's no reason why we can't make resilience and redundancy elastic too.
TH
You may also find these of interest: