
From One Runway to Another: A supply-chain love letter from fashion to aerospace
Fast fashion is an environmental disaster but a masterclass in responsiveness. The supply chain for aerospace spares could borrow the second thing without importing the first.


There are two complaints you commonly hear in the supply chain of spares in many industries, but rarely are both uttered in the same breath. The first is that there’s too much stock. Warehouses full of parts bought years ago to hedge against a forecast that never came true – and it’s probably now slowly depreciating, and some of it even ages out before it’s ever fitted. The second is that there’s never the right stock. In aviation, that commonly means that an aircraft sits grounded waiting for one part that isn’t available in any close proximity…and subsequently, burning tens of thousands of pounds an hour while it waits.
They’re actually the same problem wearing two coats. Both come from the same habit: forecasting slow, intermittent demand off long-run historical averages, then covering the uncertainty with a big static buffer and hoping it’s sitting in the right place. You end up holding too much of the wrong thing and too little of the right thing, but ironically paying for both at once. I recently wrote about the warehousing half of this in [Just in Case], where the redundancy cushion has quietly become one of the biggest tenants in the industrial property market. This is the other half.
I’ve long been a fan of stealing the successes of other industries to help solve issues in another, and this can be one of those examples; there’s an industry that solved the responsiveness problem so thoroughly it became notorious for it, and it’s one aerospace would never normally look at:
Fast fashion.
The likes of Zara and Shein are an environmental embarrassment; but strip the disposability away and what’s left is a genuinely brilliant machine for matching supply to demand you can’t predict; and that’s a model worth borrowing.
This article is about how their model actually works.; which bits of it survive contact with a certified aircraft part and which absolutely don’t, and a small piece of maths that puts a number on the prize.
What the rag trade worked out
Most people picture fast fashion as cheap clothes made fast. The interesting part is how the supply chain decides what to make.
Start with demand sensing. Instead of forecasting a whole season from last year’s sales and committing months ahead, Zara reads what’s selling right now, store by store, day by day, and feeds that straight back to production. Shein takes it further, watching search trends, social signals and in-app behaviour to spot a rising shape or colour before it’s really arrived. The principle is simple: forecast from signals of what’s about to happen, not averages of what already did.
Then there’s postponement, which is the practice of staying deliberately undecided. You build generic, half-finished stock and commit to its final form as late as you possibly can, once you know what’s actually wanted. Zara holds undyed fabric and colours it late, so there’s less guessing.
Add small in-season batches. Zara launches a style in runs sometimes under a thousand, watches the sell-through, then reorders only the winners, restocking stores twice a week. Shein tests with as few as a hundred units and scales only what moves. And they position stock close to where it’ll actually be bought. They pay a bit more per unit and accept it, because the saving comes from almost never being badly wrong about what’s needed, or where.
So in the broadest possible principles aircraft supply chain should aim to mimic:
Sense fast
Commit late
Position close
From that 30,000 ft view, none of that logic is really specific to clothes.
Some of it doesn’t fly
I’m just a bloke thinking about stuff, and I’m not closely wedded to the intricacies of this industry – so I’m sure a maintenance planner would spot a lazy analogy instantly, and they’d be right to. The broad theory translates, but there’s reasons if works flawlessly in fashion context, but there may be a few creases to iron out before being adopted by aviation.
Fashion demand is high-volume and forgiving. A missed t-shirt sale costs a markdown. Miss a spare and you might ground an aircraft or, far worse, you’re into safety-critical territory where the cost isn’t a markdown at all. Spares demand is also a different statistical animal: low-volume and lumpy, long stretches of nothing punctuated by the odd spike. Realiostically, that can’t be smoothed with the methods a fashion retailer uses. Also, none of it escapes regulation, traceability and certification, which fashion simply doesn’t carry in the same way that parts for aircraft does; but, software, barcoding and inventory management could develop alongside this to make this more or a practical reality./.

[FIGURE 3 here: mapping table, “What packs, and what gets left at the gate”]
As I see it, the principles seem to split into three piles:
1. Demand sensing ports over relatively cleanly: swap store sell-through for part removals, condition data and how hard the fleet’s being flown.
2. Distributed positioning ports across quite well too, with solid maths behind pooling stock rather than scattering it. Paying more per part to dodge a grounded jet is a trade aerospace already understands.
3. Admittedly, the Postponement only half-travels across: you can hold a common module and finalise its configuration late, but only where the part and its certification allow it. Small test batches mostly don’t, because certification costs and supplier minimums fight you. And the disposability doesn’t travel at all, which is rather the point.
There’s an irony staring at us as far as I can see it - the maintenance world already adopts fast fashion’s worst feature. Industry estimates put the share of spares that expire unused at something like a fifth to a third of them. So it’s a waste bill that’s already being paid, although the responsiveness it’s supposed to buy isn’t being collected.
The buffer you can throw away
A number can be attributed to assist in this, and it’s built on textbook inventory maths, not anything I’ve invented. The safety stock you hold to hit a service target is roughly the service factor, multiplied by how variable demand is, multiplied by the square root of the lead time. In plain terms, your buffer grows with two things: how wrong your forecast tends to be, and how long you wait for resupply.
Responsiveness attacks both, separately. Sense demand better and you shrink the forecast error. Resupply faster and you shrink the lead time. Because the two multiply together, the gains compound.
If we take a basic aircraft part – something like a valve - say it turns over about two a month, lumpily, with a demand spread of three units. Lead time from the manufacturer is six months, and you want to cover ninety-five times out of a hundred. The textbook buffer for that works out at roughly twelve units, sitting on top of the dozen already in the pipeline. Two dozen units of a part that moves twice a month. That’s the dead-capital story in one part number. The below graph should help to illustrate that.
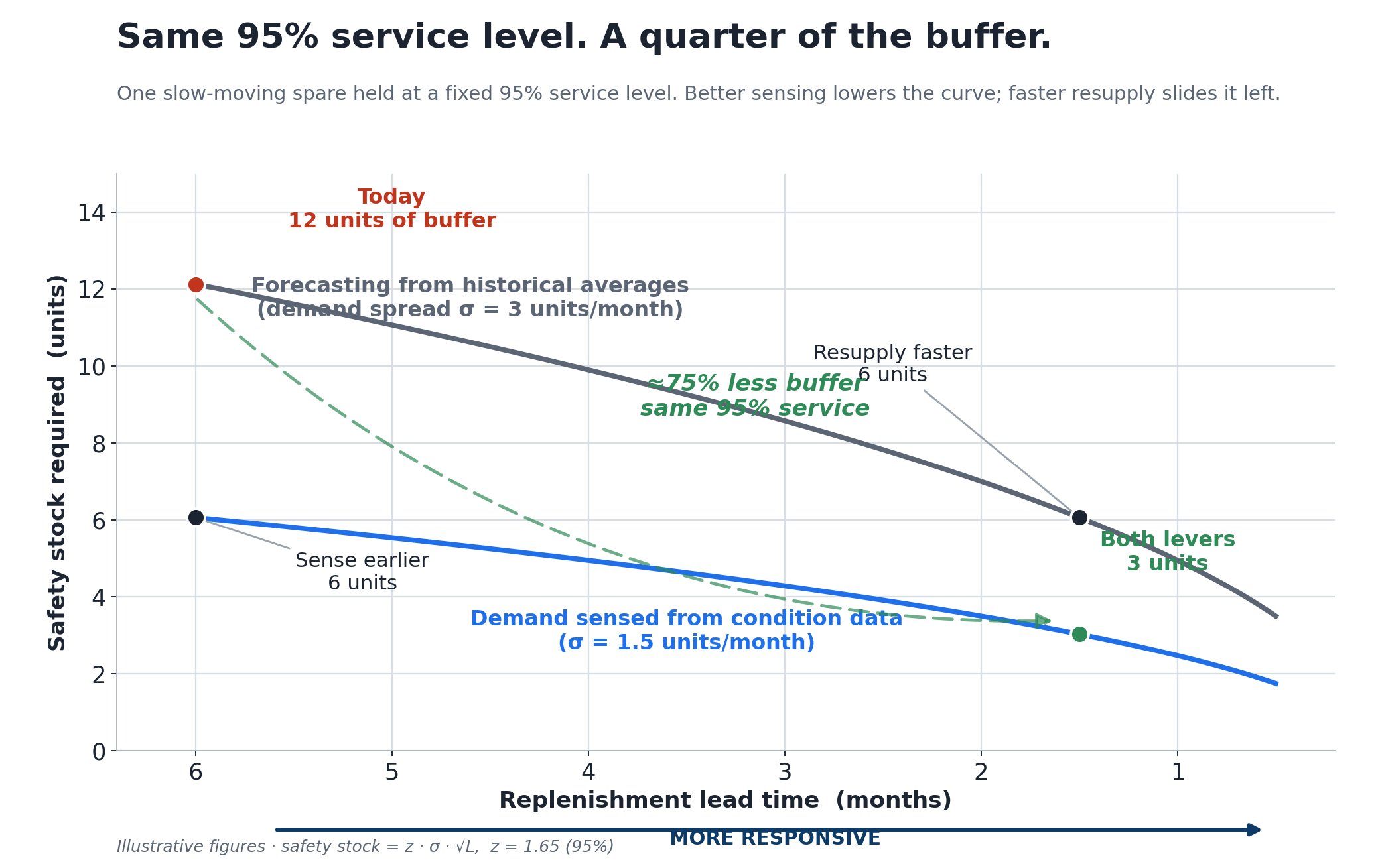
To improve responsiveness, we should consider feeding in condition-monitoring data so the forecast error roughly halves, and the buffer falls to about six. Separately, pre-position stock or stand-up regional repair (so resupply drops from six months to six weeks), and simultaneously the buffer falls to about six again, this time with far less in the pipeline too. Do both and you’re near three units, for the same ninety-five percent cover. Mathetmatically, this leads to suggest to about quarter of the buffer, with the same identical protection.
I will expressly state that this is a very linear model, and as such, can’t ever really be deemed as immediately and universally accurate in realistic context. With demand which is typically very lumpy for aircraft parts, the tidy bell-curve formula is only a rough guide; and a proper model would model the lumps directly. For genuinely intermittent parts you’d reach for something like Croston’s method, which forecasts the size of demand and the gap between demands separately, so all those zero months don’t drag the estimate to mush. The exact figures shift when you do it properly. The shape of the result doesn’t: compress forecast error and lead time, and the buffer collapses while the service level holds.
Sorting the wardrobe
The catch is that not every part can move along that curve, so you have to sort them first.
Two questions do the sorting:
How lumpy is the demand; and
Can the part be made responsive at all, meaning can you sense its demand early, resupply it quickly, and is it free of certification locks.
Cross those and you get four homes:
1. Steady demand you can sense gets responsive replenishment, the fast-fashion zone: thin buffer, sense and react.
2. Lumpy but responsive gets the same reflex with a slightly deeper cushion for the spikes.
3. Predictable but hard to move runs happily on a classic reorder point.
4. And the lumpy, hard-to-move, often safety-critical parts get a deep buffer or, better, a shared pool.
That last pile is where positioning earns its keep. Pool the same slow mover across several operators instead of everyone holding their own, and the arithmetic of pooling means the combined buffer shrinks roughly with the square root of how many holdings you’ve merged. Four separate stashes pooled into one need about half the total safety stock for the same cover. For the parts that can’t be made responsive, that’s the lever that’s left.

Keep it honest
Nearly sounds too good to be true, doesn’t it? So let me be clear about the line you can’t cross, and probably is the large part why this model hasn’t been fast-tracked into the supply chain before.
You cannot fast-fashion a safety-critical certified part (for regulatory reasons predominantly, but there’s practical merit to the approach aswell, of course). Postponement stops where certification of a configuration begins.
Traceability is non-negotiable, sole-source lead times are real and often immovable, and “sense and react” is never a licence to thin the buffer on the part whose failure is catastrophic.
So the lesson, or the thing to borrow is the responsiveness philosophy, applied carefully, on the parts that can take it - sensing earlier, committing later, and aiming to position smarter.
Position stock closer; sense demand sooner; commit later where the part lets you; and pool the rest in the open.
TH