
Clean Your Clouds: Carbon Flow Failover should be the next evolution in sustainable infrastructure
What if data redundancy routed to the greenest and cleanest cloud, and not the nearest? Microsoft and Google only solved half of the equation with Carbon-Aware Compute - and there's a low hanging frui

Redundancy is the backbone of reliable infrastructure — but it's also a silent contributor to waste. My previous article on the Elastic Failover Exchange enables a methodology to monetize and optimize the use of such failover capacity. But in the event that it's not been offered as monetized infrastructure, could it be nominated for a sustainable purpose?
Most modern data centers provision twice the capacity they need to ensure business continuity. One set of servers sits idle or “warm,” consuming power for the rare moment it’s needed. The expense and energy comsumption is the collateral damage for uptime; but in the era of climate consciousness, perhaps we should be aiming to move towards a design which can account for both resilience and responsibility.
The Concept: Carbon Flow Failover
What if your disaster recovery site wasn’t just the nearest, but the greenest?
Carbon Flow Failover is an concept that uses real-time carbon intensity data to influence where workloads fail over during an outage or surge.
Instead of defaulting to a fixed disaster recovery site, the system dynamically chooses the location with the lowest environmental impact at that moment.
This is a great time to implement such a protocol, as developments in the infrastructure management are starting to align with the corporate and social responsibilities for data centers.
Energy grids are no longer static. Renewable penetration varies hourly and regionally.
Infrastructure is programmable. With cloud-native tooling, dynamic provisioning is the new norm.
Sustainability is business critical. Carbon flow failover supports corporate environmental, social and governance goals; and can reduce scope 2 emissions (indirect electricity use).

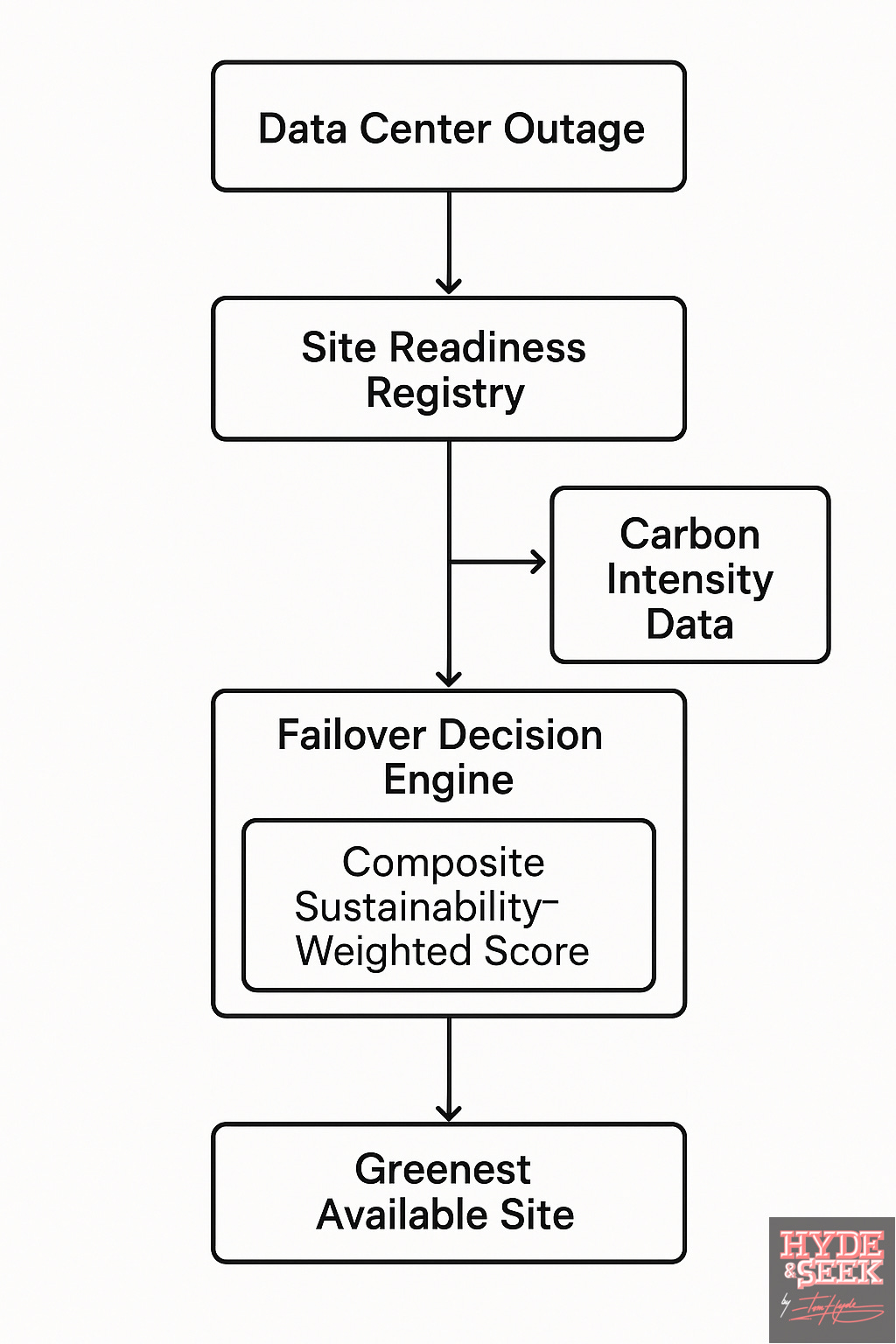
How It Works
1. Carbon Signal Ingestion - continuously ingest real-time carbon intensity data for each region/data center:
Sources: WattTime, ElectricityMap, or local grid operators.
Metrics include: gCO₂eq/kWh, marginal emissions, and renewable % of grid mix.
2. Site Readiness Registry - Maintain a dynamic inventory of standby or disaster recovery-capable sites with:
Live health status (infrastructure, connectivity, network latency)
Available failover capacity
Local carbon intensity score
3. Failover Decision Engine - A policy-based decision engine evaluates:
Calculates a composite sustainability-weighted score for each failover site.
Selects the site with lowest net impact within SLA bounds.
4. Workload Migration / Activation - Data Redundancy workloads are spun up or scaled in the selected green region [Tools: Kubernetes federation, HashiCorp Nomad, OpenShift, etc]. DNS/load balancer redirects traffic accordingly.
5. Reporting & Audit - System logs the failover action, location, carbon delta, and time; and subsequently generates reports for ESG compliance or carbon accounting.
A suggested implementation stack
There's plenty of integrations that could work; and will more likely depend on the individual systems, firmware and softweare being utilized within the infrastructure itself; but some suggestions could be:
Carbon Data Feeds - WattTime API, ElectricityMap API, NREL open datasets
Monitoring/Health Checks - Prometheus, Grafana, Datadog
Decision Engine - Custom Python/Go service, Terraform policies, Open Policy Agent
Workload Orchestration - Kubernetes multi-cluster, Nomad, ArgoCD
Failover Routing - Cloudflare, NS1, AWS Global Accelerator, Akamai
Audit/Compliance - ESG tools (Watershed, Persefoni), carbon APIs, ledger logging
Superior Sustainability Scoring - Benefits at a Glance
Traditional Failover
Always-on, static location
Ignores carbon impact
May waste energy 24/7
Single failover path
Focus: uptime only
Carbon Flow Failover
Adaptive location based on real-time data
Optimized for green energy availability
Cold/warm Data Redundancy can be spun up dynamically
Multiple flexible Data Redundancy destinations
Focus: uptime + sustainability
What’s been done, and the enhancement opportunity
While carbon-aware scheduling has gained momentum in cloud computing (see Google’s work on Carbon-Aware Compute, or Microsoft’s work on carbon-intelligent load shifting), applying this explicitly to failover and redundancy systems is still nascent and largely untapped.
This is a space ripe for innovation and policy shaping, although many of the solutions would be transferable from existing systems and architecture through integrating API protocols.
The above methodology addresses some of the fundamental gaps in the current models operating by Google and Microsoft:
Google’s Carbon-Aware Compute shifts jobs to cleaner regions during low-priority batch processing.
Carbon Flow Failover activates on-demand in response to outages — it includes emergency resilience, not just scheduled workloads.
Microsoft’s Carbon-Intelligent Load Shifting focuses on batch jobs in flexible time windows.
I'm proposing multi-region active-passive failover optimized for latency, sustainability and Service Level Agreements, useful for production systems.
Google and Microsoft are both focusing on internal cloud provider operations.
This proposed model is infrastructure agnostic: applicable to any enterprise or hybrid cloud with multi-site Data Redundancy.
Current methods use basic regional CO₂ averages.
This model proposes the use of marginal emissions, time-of-day signals, and forecasted grid carbon intensity. [API Integration to WattTime API, ElectricityMap API, NREL open datasets]
In the Google/Microsoft systems, sustainability is only considered post-deployment.
This model suggests making it part of the failover decision tree itself — sustainability-aware resilience, not just compute.
Conceptual Growth and Development Potential of Carbon Flow Failover
Forecast-Based Carbon Pre-Warming - Use machine learning to pre-warm standby sites before a predicted high-carbon period, shifting workloads proactively.
Carbon Budget-Aware Disaster Recovery Policies - Allow organizations to set annual/monthly carbon budgets for failover; failover happens only if the action stays within the carbon envelope.
Smart Disaster Recovery Escalation Protocols - In cases of multi-site failure, the system can choose partial failover to multiple greener sites rather than one dirty but close site.
Carbon-Aware Service Level Agreement Tiers - Offer users the ability to select Data Redundancy policies based on lowest latency, lowest cost, or lowest carbon.
Carbon Flow failover is perhaps the next frontier in sustainable cloud infrastructure. It's the convergence of DevOps, sustainability, and intelligent systems - effectively turning disaster recovery from a reactive necessity into a strategic lever for environmental stewardship.
TH
You may also find these of interest:
Redundancy Revenue: An Elastic Failover Exchange to turn your competitor's downtime into dollars

Redundancy Today: Safe but Wasteful
The Proteus Protocol: How to rollout AI-ready data centers faster than your competitors for next-to-nothing

I'd forgive you if you'd never heard of Proteus before.
I'll be your server today: A novel wafer design for a better data center solution

This could either be a billion-dollar idea or a complete failure. However, as data centers begin to reach hyperscale, the construction challenges - and subsequently the costs associated in overcoming them - are soon becoming prohibitive.